

How does indexing make databases faster?


We know creating indexes for those columns that are frequently used makes the read operations faster. But what exactly happens and what leads to this increase in performance of read operations. Lets try to understand this in this article with a simple example.
First lets understand how the records are stored in memory. Each row is serialized and is stored as bytes. Our entire memory is divided into blocks and the rows get stored in the blocks depending upon the size of the blocks. For example, if out memory is divided into blocks each of size 1000 B, and each row (record) is of size 200 B , then each block can store 5 rows (1000/200).
While searching for a record, an entire block is read at once, the record for which we are searching for is considered, others are discarded.
With this in place, lets look at an example.
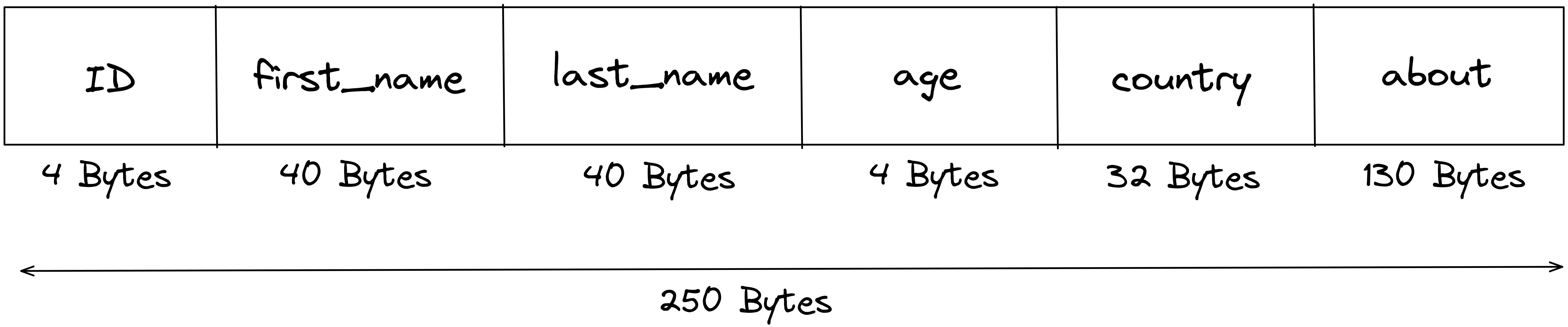
Lets consider a record in which we have the fields - ID (Primary Key), first name, last name, age, country and about. The entire record requires 250 Bytes of space in the memory.
Lets assume our memory blocks are of size 1000 B, so each block can store 4 (1000/250) such records. Lets say we have 200 such records, the we would need (200/4) 50 memory block to store these 200 records.
For our example's sake, lets assume each block read takes 1 ms. So x block reads are going to take x ms.
Now consider a query where we need to return all the records having age as 30.
Without Indexing
Now let us understand how this query will get executed without any indexing support. We will have to do a sequential scan of all the blocks storing the records. For each record which matches the condition is stored in an output buffer . For our case, we have 50 block and each block read will take 1 ms (since the entire block is read at once) , hence the time taken for the execution of our query will be 50 ms and we return the output buffer.
With Indexing
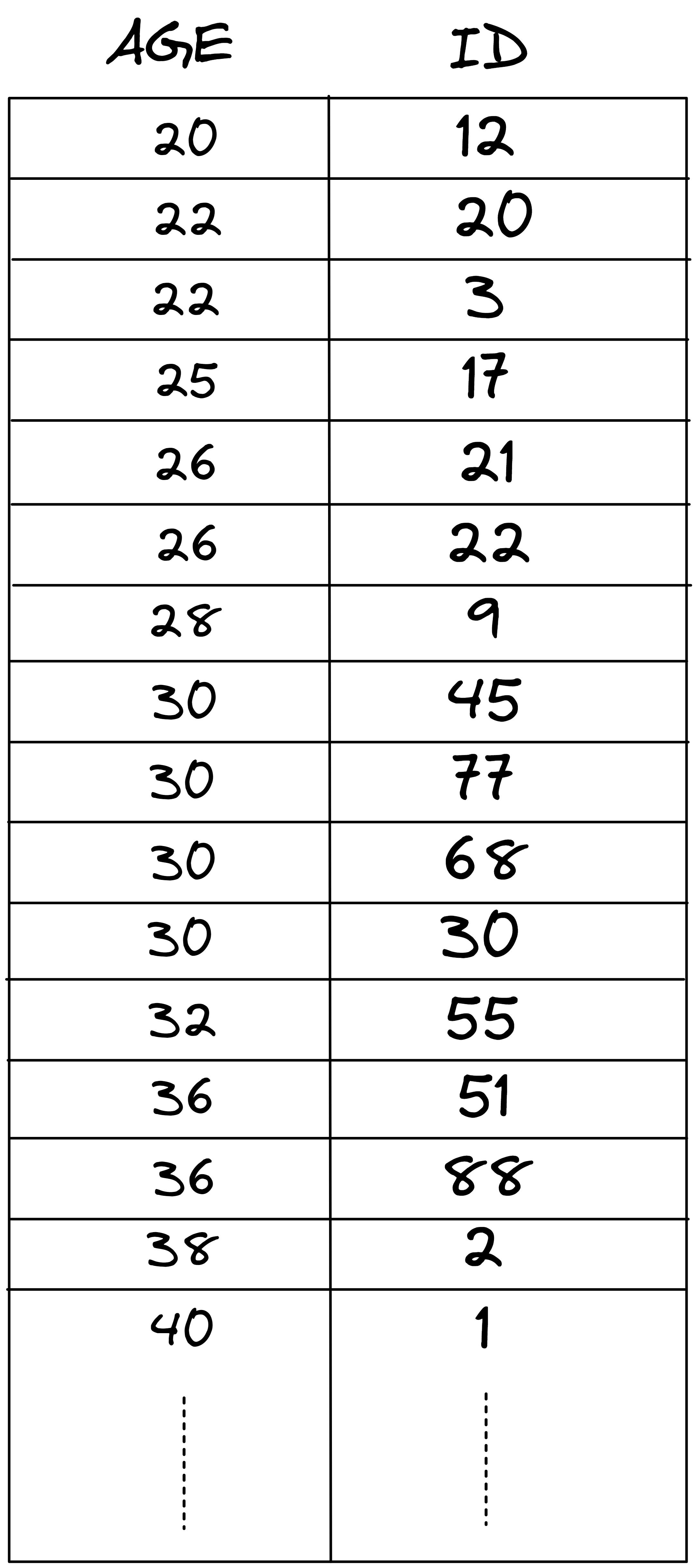
We create an index on our age column. Index is basically a 2 column table. Our index column contains age and id (primary key) ordered by age. Simply put, its a mapping of age to ids from our main table ordered by age.
Our index table will itself be serialized and stored in memory blocks. Lets see how many blocks we need.
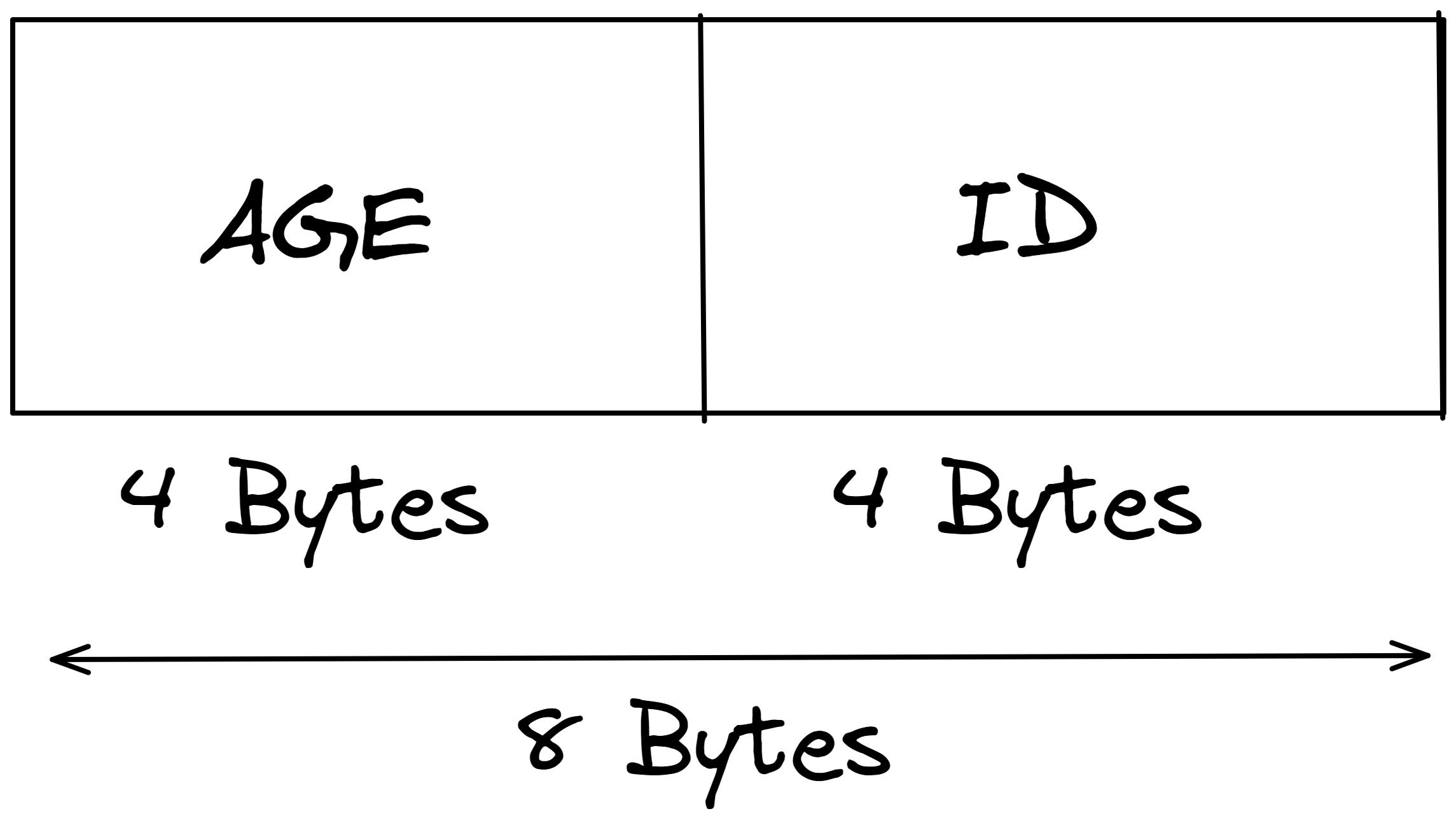
Age and Id both require 4 B each, so each record in index will take 8 B. Now our blocks are of size 1000 B each, so each memory block can have (1000/8) 125 records. We have 200 such records, so we need (200/125 ~) 2 memory blocks.
Now lets understand how the query will be executed based on this index.
We will iterate through the index block by block (in worst case, all) and store the relevant ids that match the condition in a buffer. Then for all the relevant ids in the buffer, we will read the records from the disc and store them in the output buffer and then return the buffer.
Lets say we read both the blocks in the index, so it took 2ms. And for each relevant id found , we need to read the entire block in which it is stored. Lets say we have 5 such records on the disc, hence and additional 5 ms will be consumed. So, in total, we needed 7 ms for this query to execute after indexing.
The difference in performance is super clear. From 50ms , we bought it down to 7 ms. This was the most basic way of implementing indexing, but we can further optimize this performance by enhancing our implementation of indexing.
For example, since indexes are sorted, we can stop after we cross age==30 criteria. We can also use Binary search on the age column. To reduce the number of block reads, we can use multilevel indexing (B Trees and B+ Trees), etc.
That's how powerful and important indexing is.
I hope you found the article useful.
Lets connect :
Happy Coding :) .